
This article first appeared on OneStream Software blog page by Tiffany Ma
Introduction
In the bustling world of artificial intelligence (AI) one saying perfectly encapsulates the essence of the work – “garbage in, garbage out.” Why? This mantra underscores a truth often underplayed amid the excitement of emerging technologies and algorithms used across FP&A teams: data quality is a decisive factor for the success or failure of any machine learning (ML) project.
Big data, often referred to as the “new oil,” fuels the sophisticated ML engines that drive decision-making across industries and processes. But just as a real engine cannot run effectively on substandard fuel, ML models trained on poor-quality data will undoubtedly produce inferior results. In other words, for AI in FP&A processes to prove successful, data quality is essential. Read on for more in our first post from our AI for FP&A series.
Understanding the Importance of Data Quality
Data scientists spend 50%-80% of their time collecting, cleaning and preparing data before it can be used to create valuable insights. This time investment is a testament to why “garbage in, garbage out” isn’t a warning but a rule to live by in the realm of AI and ML. Particularly for FP&A, that rule demonstrates why skimping on data quality can lead to inaccurate forecasts, biased results and a loss of trust in ground-breaking AI and ML systems.
Unleashing Data with Sensible ML
In the current digital age, businesses have unprecedented access to vast quantities of data. The data lays a crucial groundwork for making significant business decisions. But to ensure the data available to employees is reliable, visible, secure and scalable, companies must make substantial investments in data management solutions. Why? Substandard data can trigger catastrophic outcomes that could cost millions. If data used to train ML models is incomplete or inaccurate, this could lead to inaccurate predictions with consequential business decisions that lead to loss of revenue. For example, if bad data causes incorrect forecasts about demand, this could lead to the company producing too little or too much of the product, resulting in lost sales, excess inventory costs, or rush shipments and overtime labor.
Contrary to “most” predictive analytics forecasting methods, which generate forecasts based on historical results and statistics, OneStream’s Sensible ML incorporates true business insights. These insights include factors such as events, pricing, competitive data and weather – all of which contribute to more accurate and robust forecasting (see Figure 1).
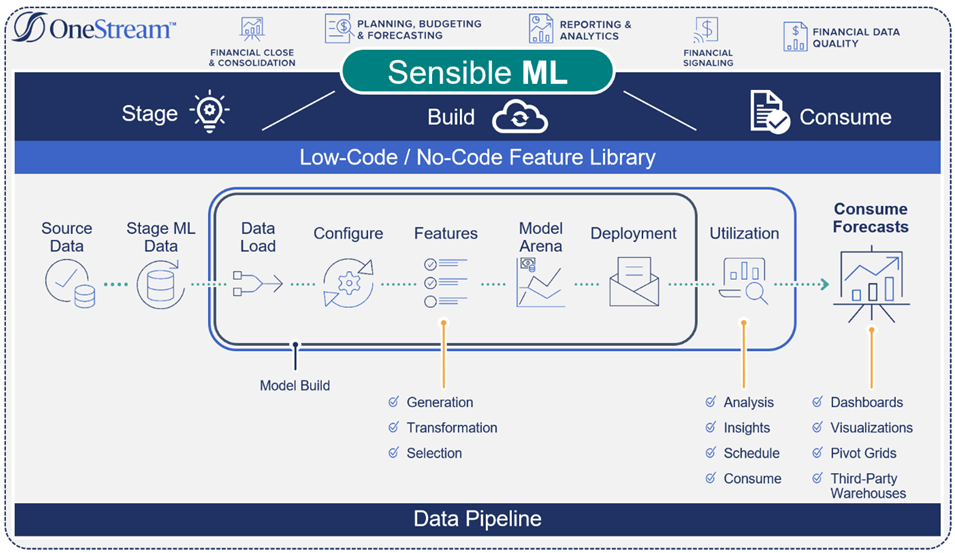
Managing Data End-to-End
FP&A and operational data plays a pivotal role in the success of any machine learning forecasting scenario. However, to create purpose-built data flows that can efficiently scale and provide exceptional user experiences, advanced solutions – such as Sensible ML – are necessary. Sensible ML can expedite and automate crucial decisions throughout the data lifecycle, from the data source to consumption (see Figure 2).
Advanced data flow capabilities encourage the following:
Trust in the governance of data by ensuring data privacy, compliance with organizational standards and transparent data lineage traceability.
Enriched internal data with external sources by adding external variables that fuel improvements (e.g., retailers adding external variables to existing data to better profile and recognize customer needs for recommendations, upselling and cross-selling).
Accelerated data processing by continuously monitoring quality, timeliness and intended context of data.
Sensible ML leverages OneStream’s built-in data management capabilities to ingest source data and business intuition. How? Built-in connectors automatically retrieve external data such as weather, interest rates and other macroeconomic indicators that can be used in the model-building process. While Sensible ML then automatically tests the external data sources without any user intervention, users ultimately decide which data to use.
Using Sensible ML’s Built-in Data Quality
Sensible ML can bring in detailed operational data from any source, including point-of-sale (POS) systems, data warehouses (DW), Enterprise Resource Planning (ERP) systems and multi-dimensional cube data.
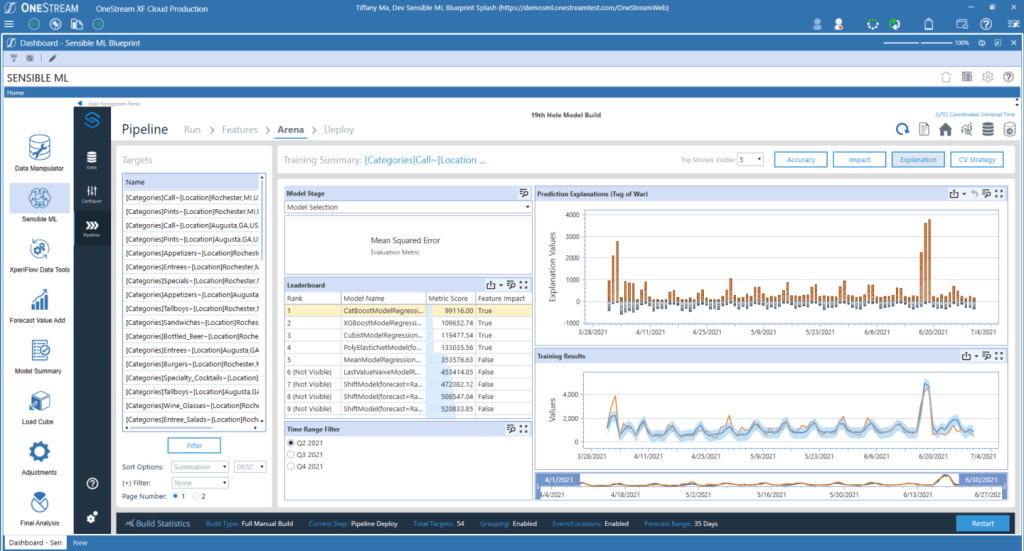
The data quality capabilities in Sensible ML provide some of the most robust capabilities available in the FP&A market. Those capabilities include pre-and post-data loading validations and confirmations, full audit, and full flexibility in data manipulation. In addition, Sensible ML’s data management monitors the way data curation typically behaves and then sends alerts when anomalies occur (see figure 3). Here are a few examples:
Data Freshness – Did the data arrive when it should have?
Data Volume – Are there too many or too few rows?
Data Schema – Did the data organization change?
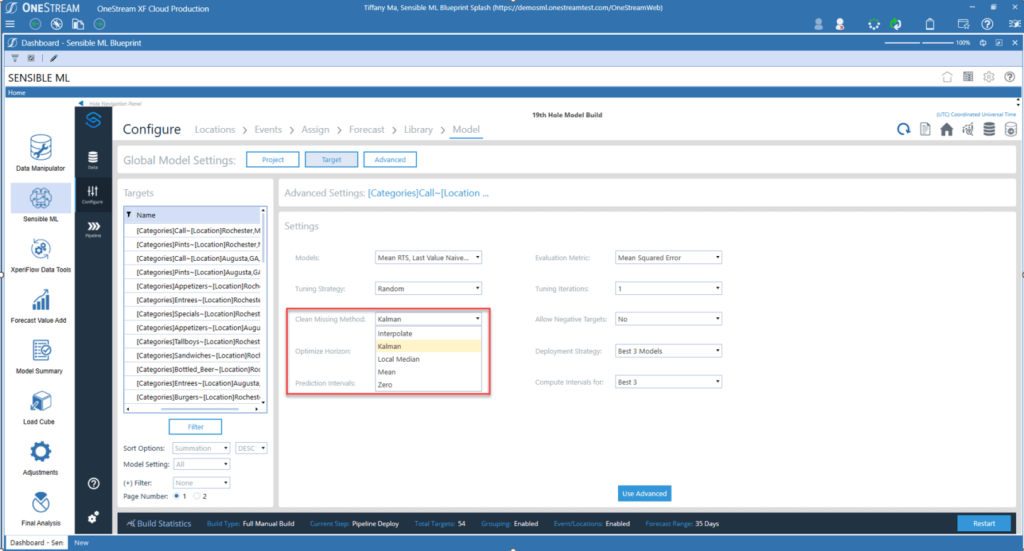
In Sensible ML, an intuitive interface offers drop downs with the most performant and effective data cleansing methods, allowing business users of any skillset to run the entire data pipeline from start to finish.
Conclusion
Ensuring data quality is not just a box to be checked in the machine learning journey. Rather, data quality is the foundation upon which the entire edifice stands. As the boundaries of what’s possible with ML are continually pushed, the age-old “garbage in, garbage out” adage will still apply. Businesses must thus strive to give data quality the attention it rightfully deserves. After all, the future of machine learning is not just about more complex algorithms or faster computation. Producing accurate, fair and reliable models – ones built based on high-quality data – are also essential to effective ML.
Learn More
To learn more about the end-to-end flow of data and how FP&A interacts with data, stay tuned for additional posts from our Sensible ML blog series. You can also download our white paper here.

